![[新機能] Amazon Redshift S3イベント統合による Auto-copy が一般提供開始したので試してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[新機能] Amazon Redshift S3イベント統合による Auto-copy が一般提供開始したので試してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。Amazon S3からAmazon Redshiftへのデータ取り込みを簡素化するAmazon Redshift S3イベント統合による「Auto-copy」機能が一般提供開始されました。この新機能により、追加のツールやカスタムソリューションを必要とせずに、S3からRedshiftテーブルへの継続的なファイル取り込みが可能になります。早速、試してみます!
S3 イベント統合による Auto-copy とは
Auto-copy 機能は、S3イベント統合を活用して、シンプルなSQLコマンドでAmazon S3からAmazon Redshiftへのデータ自動ロードを実現します。
- カスタムソリューションなしで自動的かつ増分的なデータ取り込みが可能
- 追加コストなしで利用可能
- 既存のCOPYステートメントをAuto-copyジョブに変換可能
- ロード済みファイルを追跡し、データの重複を最小限に抑制
- JDBCやODBCクライアントを使用して簡単にセットアップ可能
- 低品質データファイルの自動エラー処理
- 各ファイルを1回だけロードする仕組み
前提条件
Auto-copyの前提として、RedshiftとS3バケットに設定が必要です。
-
暗号化されたAmazon Redshift Provisioned または Amazon Redshift Serverless
-
S3バケットポリシーで必要な権限を付与したS3バケット
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Auto-Copy-Policy-01", "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com", "redshift-serverless.amazonaws.com" ] }, "Action": "*", "Resource": "arn:aws:s3:::cm-datalake-20241031" } ] }※ PrincipalのServiceは、Amazon Redshift Provisioned と Amazon Redshift Serverless の両方を許可するように設定しています。
S3イベント統合の設定
準備が整いましたので、早速作成します。マネジメントコンソールから設定します。ナビゲーションペインで[S3 event Integration]を選択し、 [Create S3 event Integration]を選択。
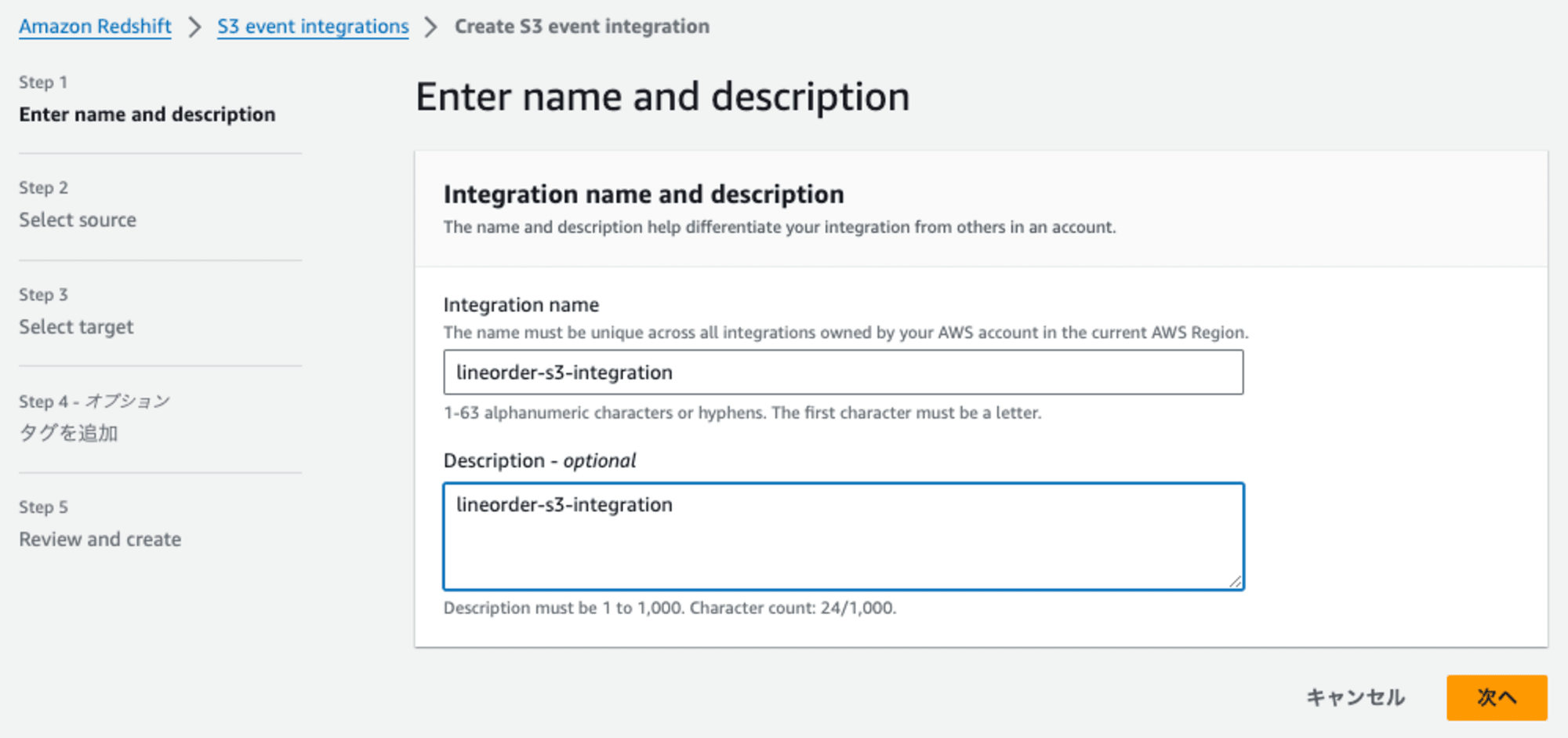
Step1: Enter name and description
Integration nameとDescriptionを入力し、[次へ]を選択
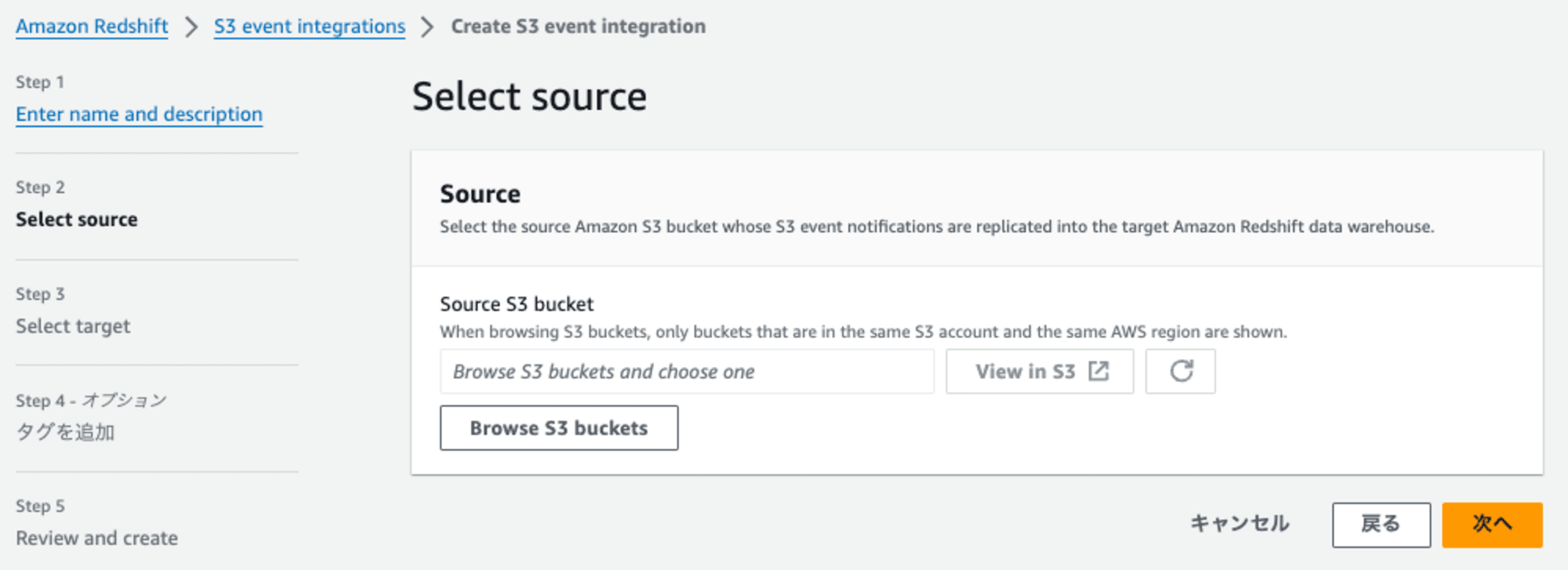
Step2: Select source
連携元となるS3バケットを指定します。[Browse S3 buckets]を押します。
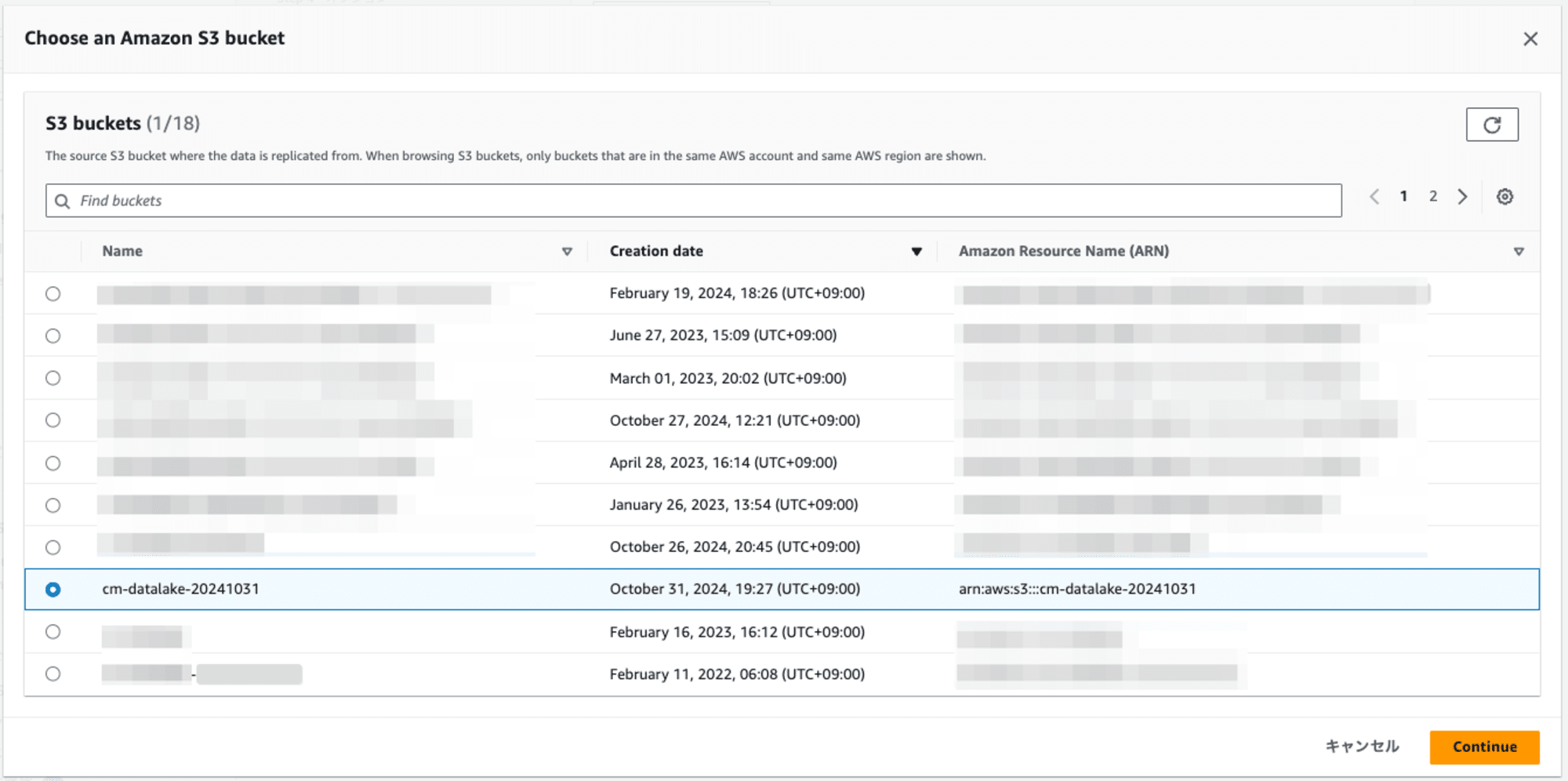
ダイアログに表示されたS3バケットの一覧の中からいずれかを選択します。
[continue] を押して元の画面に戻ります。
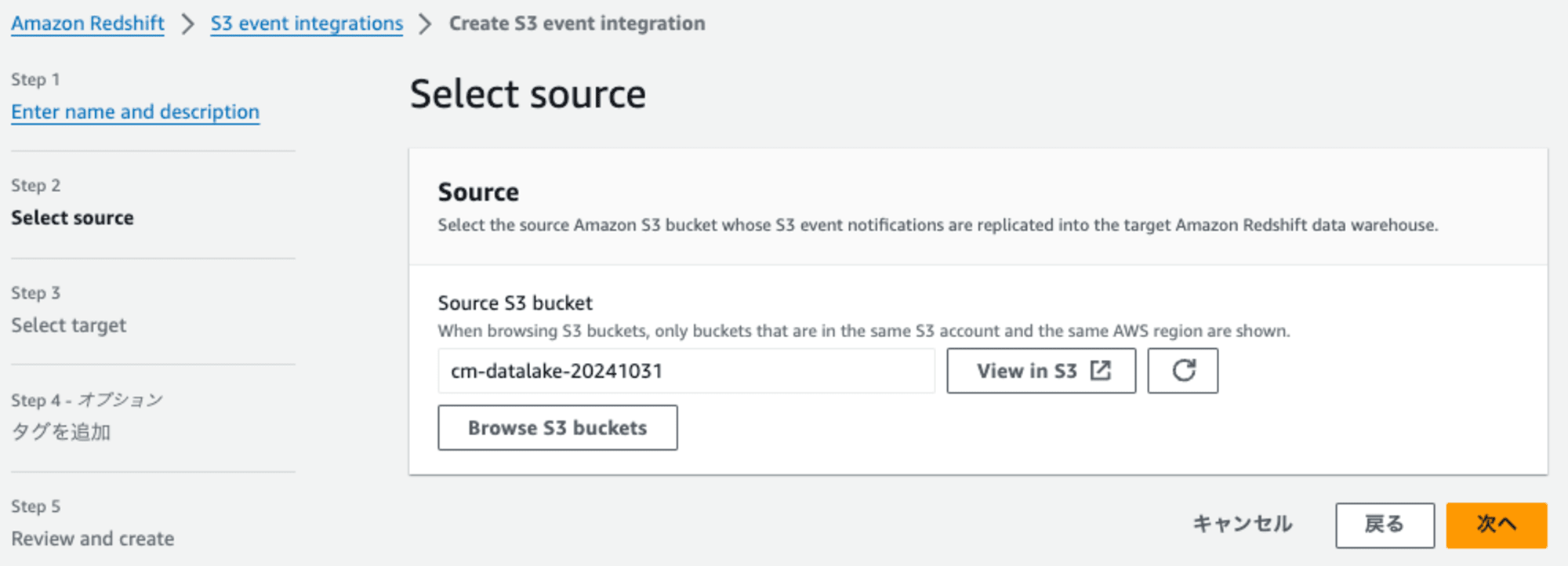
[次へ] を押して進みます。
Step3: Select target
連携先となるRedshiftを指定します。[Browse Redshift data warehouse]を押します。
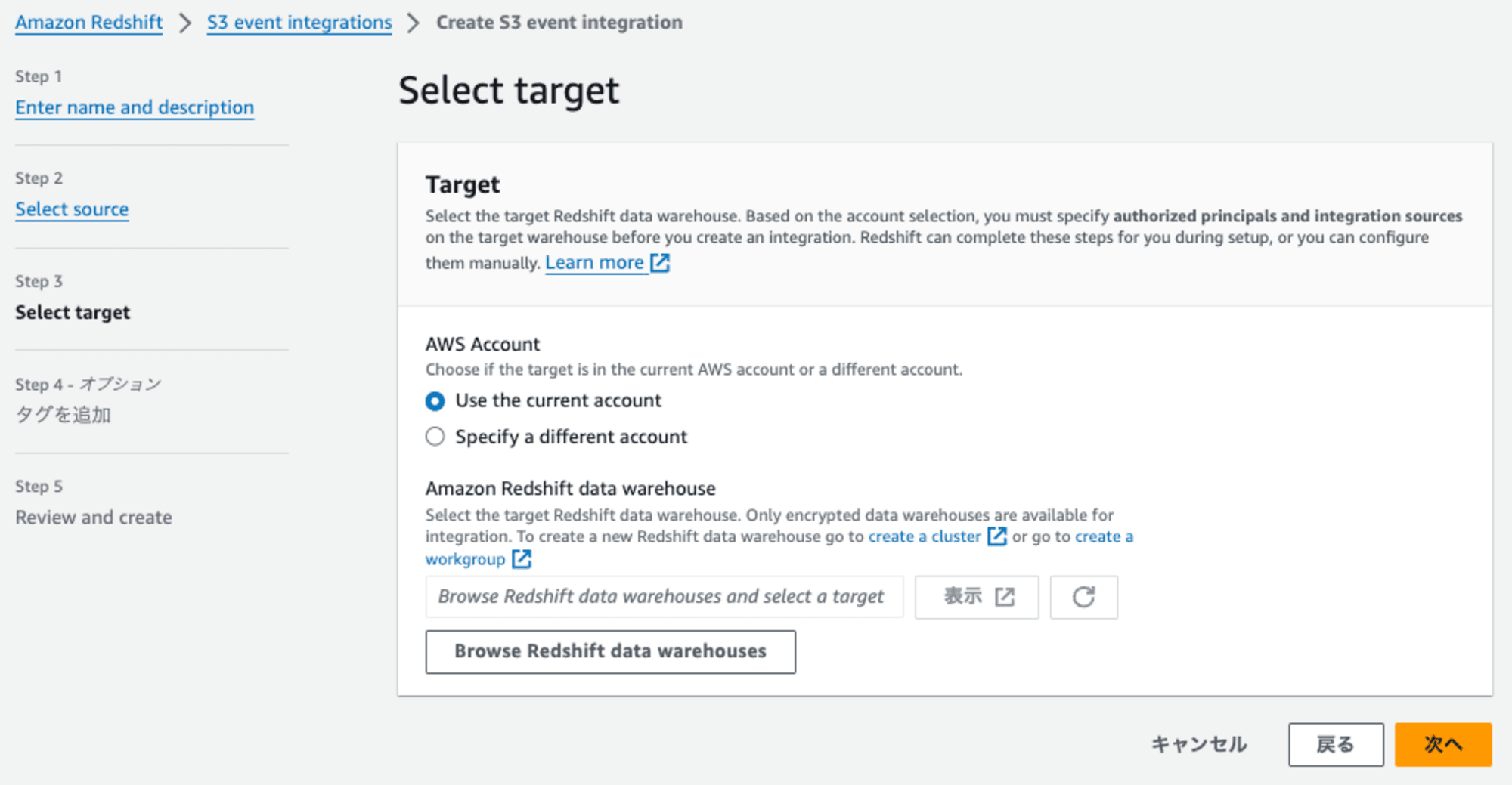
ダイアログに表示されたRedshiftの一覧の中からRedshiftを選択します。
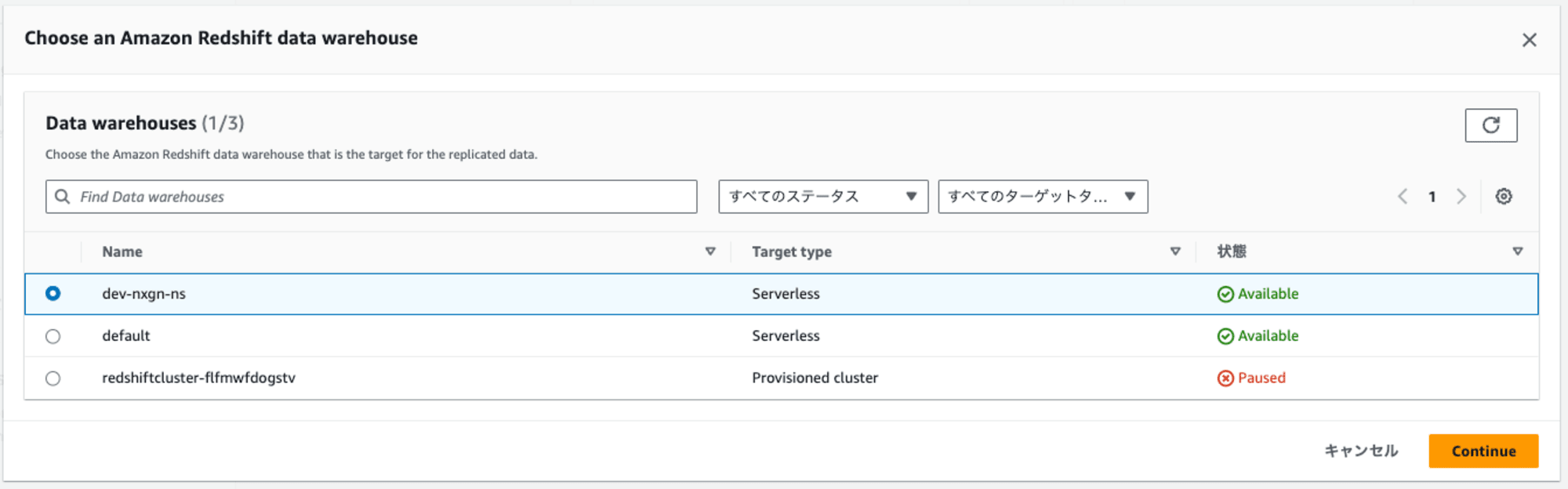
元の画面に戻ると、エラーメッセージ(リソースポリシーの修正)と[Fix it for me]オプションが表示されます。このオプションには、チェックを入れます。
その理由は、S3 event integrationを設定するには、選択したRedshiftに適切なリソースポリシーが有効になっている必要があります。[Fix it for me] オプションを選択すると、自動的に設定してくれます。
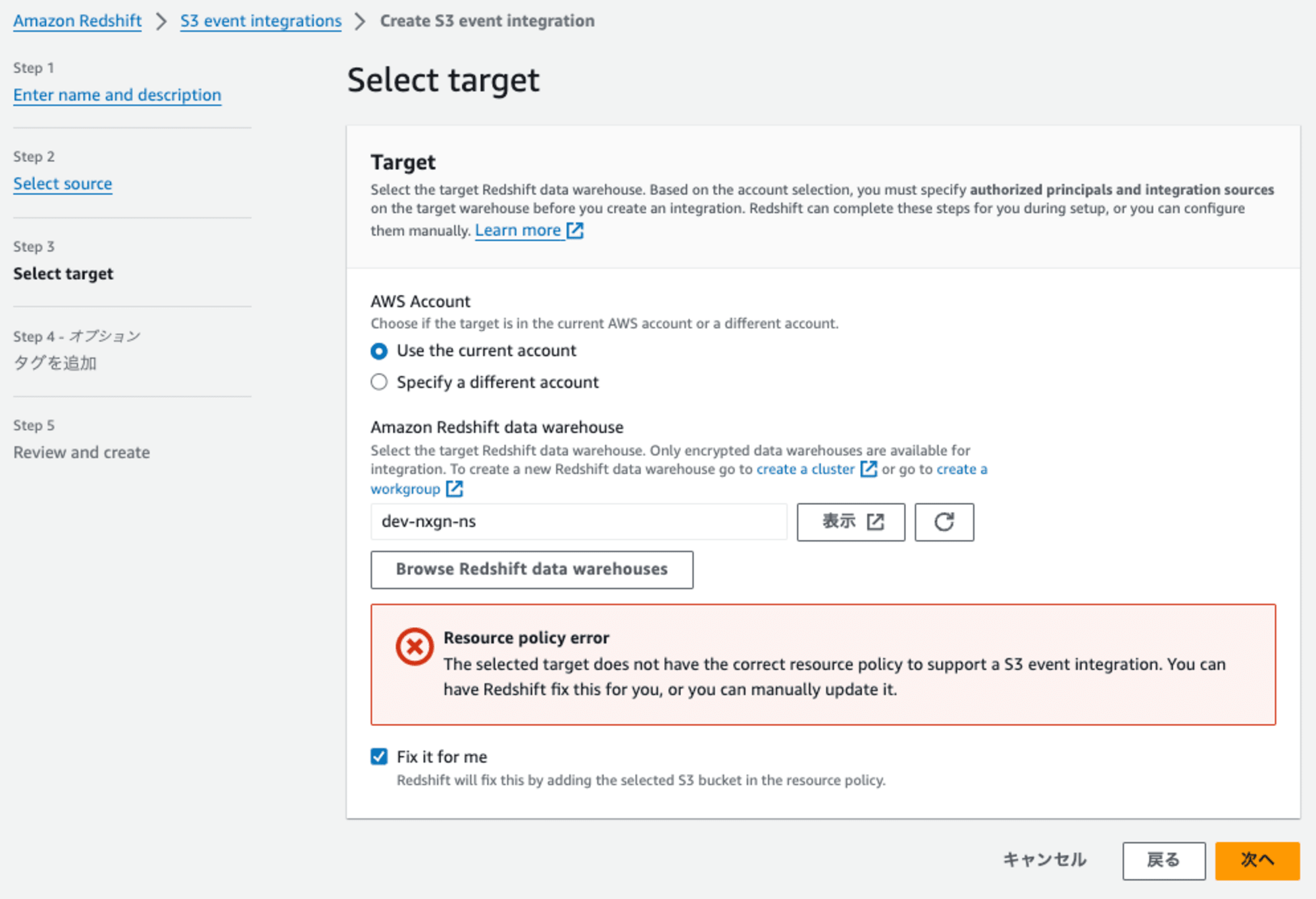
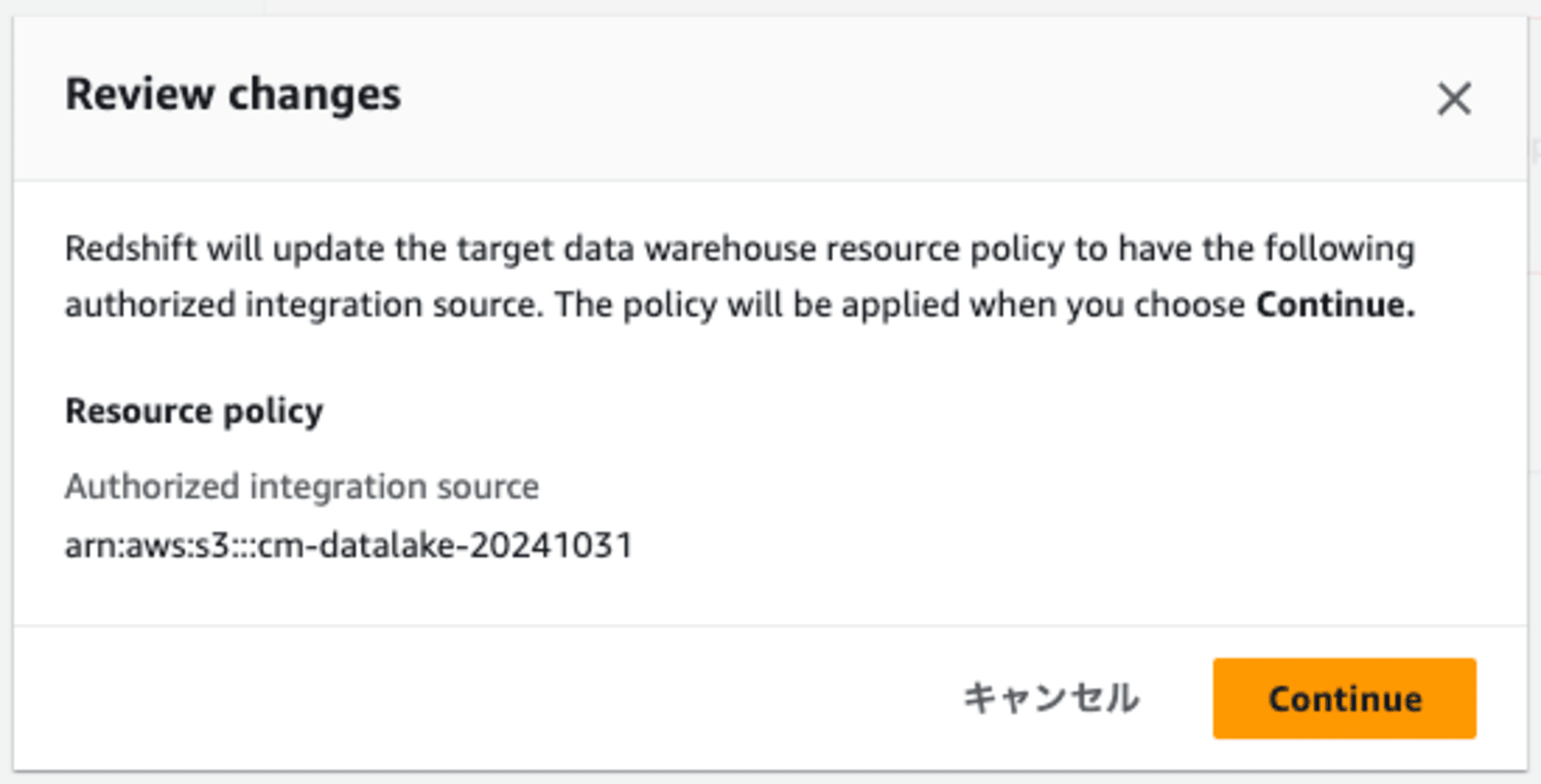
次に進むとどのような変更を加えるのかの解説が表示されます。
Step4: タグの追加
そのままで構いません。
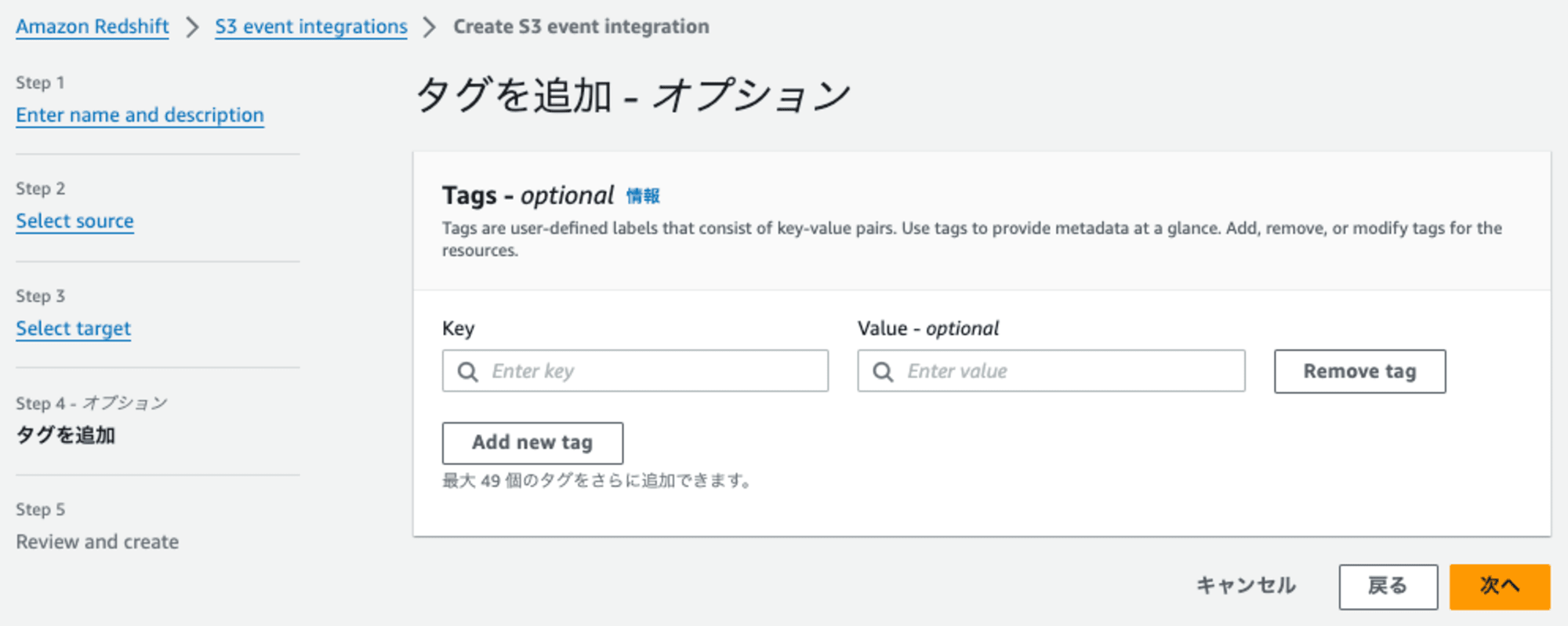
Step5: Review and create
内容を確認して、進むとZero-ETL 統合の作成します。
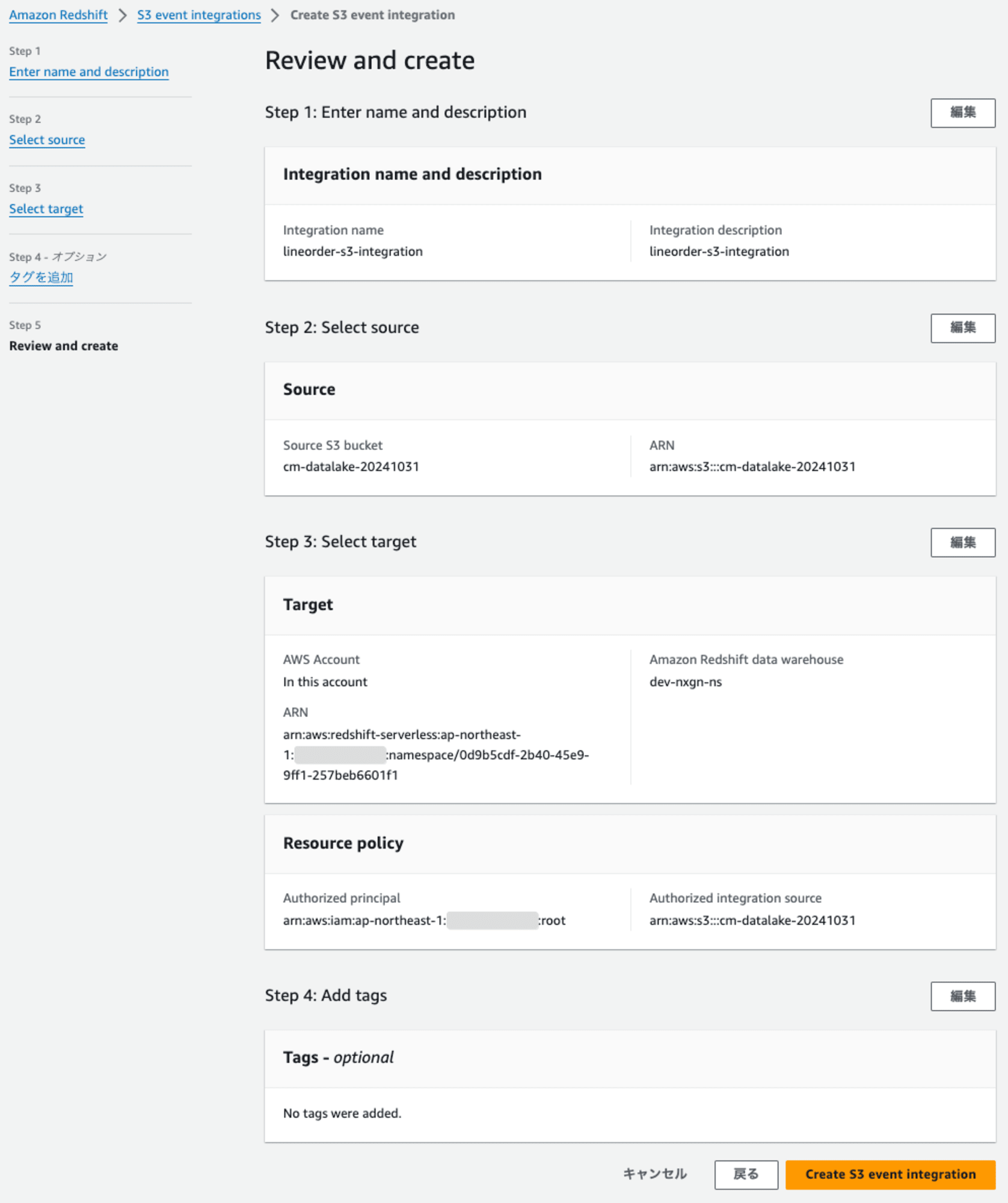
ステータスが「作成中」 となりました。
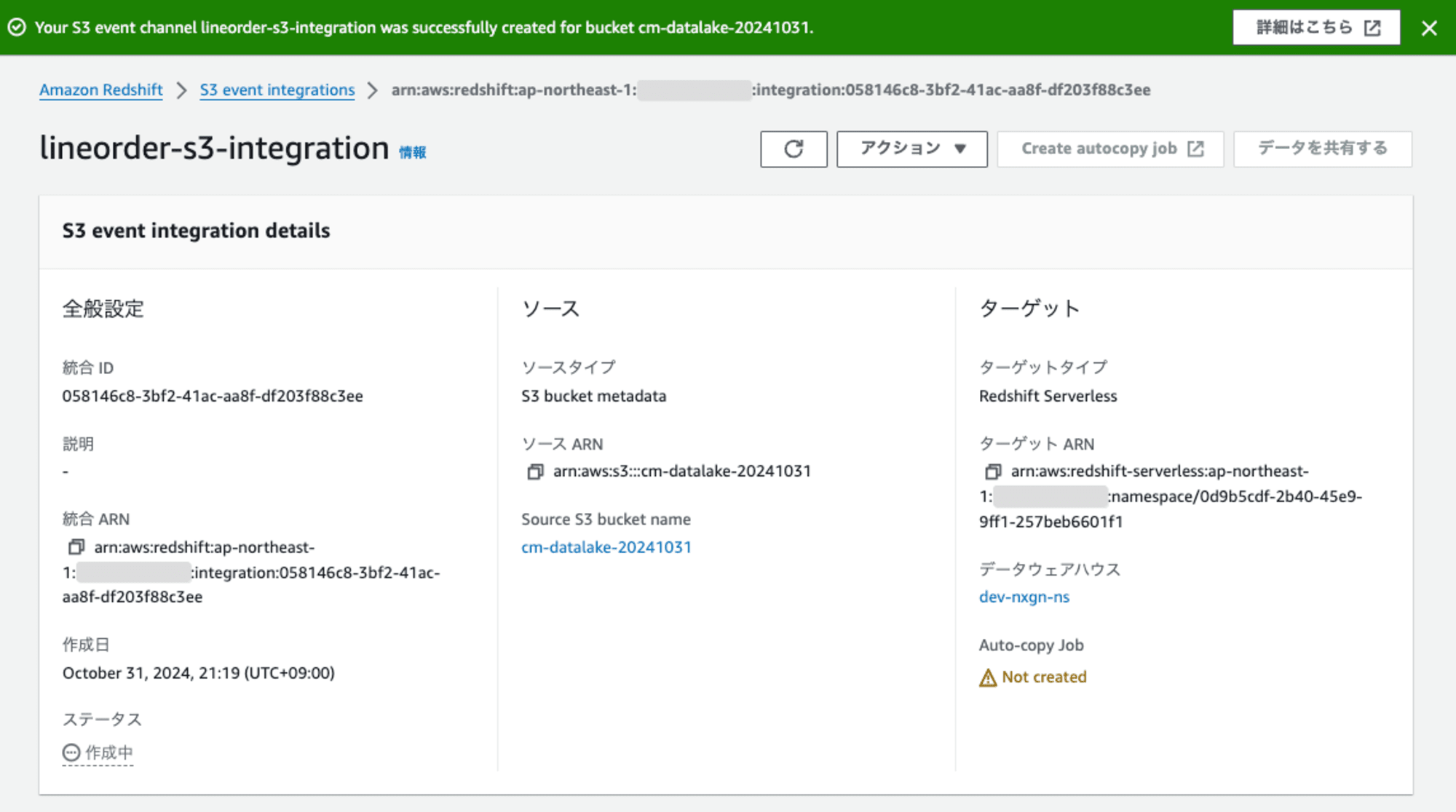
S3 event integrationの作成が完了すると、ステータスが「アクティブ」 になります。
Redshiftにテーブルを作成
Redshiftに取り込み先のテーブルを作成します。
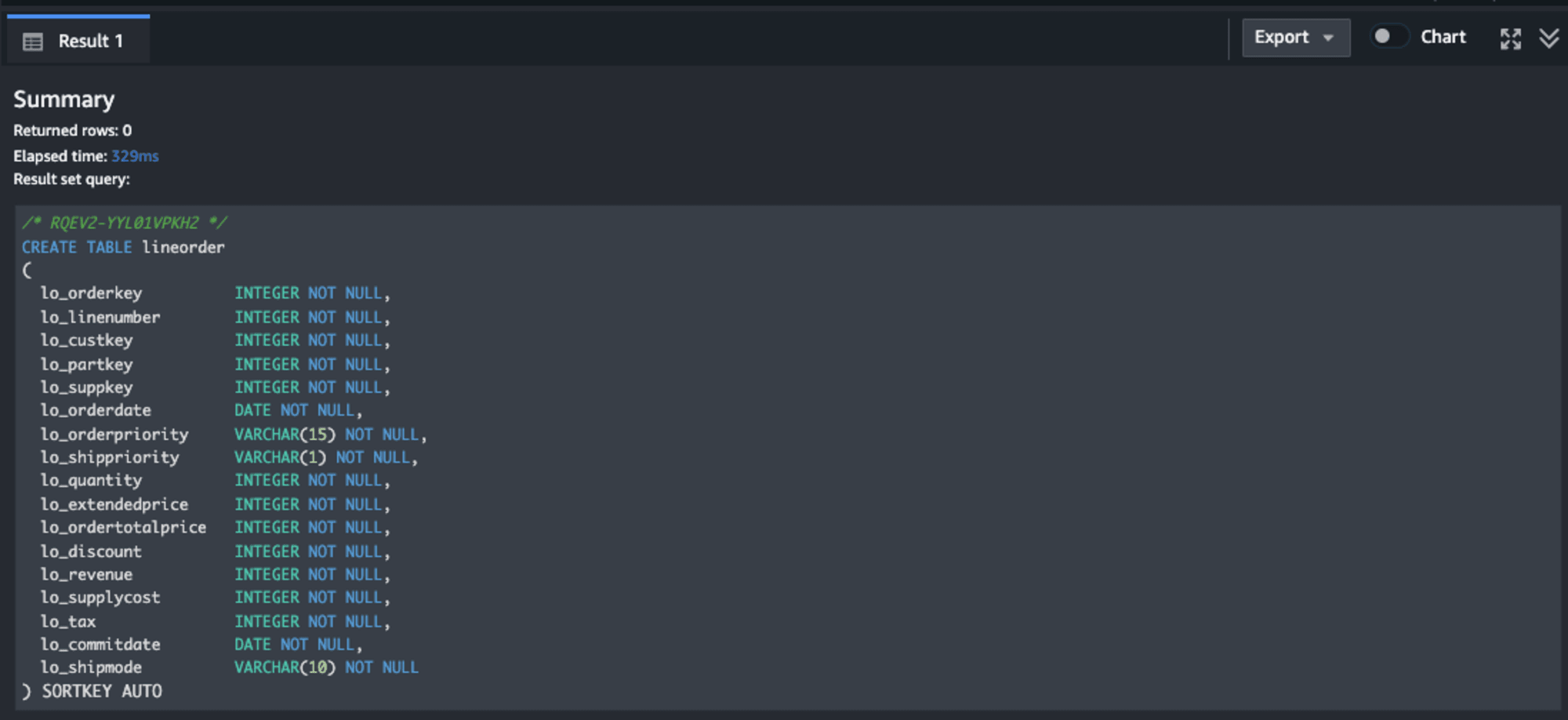
CREATE TABLE lineorder
(
lo_orderkey INTEGER NOT NULL,
lo_linenumber INTEGER NOT NULL,
lo_custkey INTEGER NOT NULL,
lo_partkey INTEGER NOT NULL,
lo_suppkey INTEGER NOT NULL,
lo_orderdate DATE NOT NULL,
lo_orderpriority VARCHAR(15) NOT NULL,
lo_shippriority VARCHAR(1) NOT NULL,
lo_quantity INTEGER NOT NULL,
lo_extendedprice INTEGER NOT NULL,
lo_ordertotalprice INTEGER NOT NULL,
lo_discount INTEGER NOT NULL,
lo_revenue INTEGER NOT NULL,
lo_supplycost INTEGER NOT NULL,
lo_tax INTEGER NOT NULL,
lo_commitdate DATE NOT NULL,
lo_shipmode VARCHAR(10) NOT NULL
) SORTKEY AUTO;
Auto-copyジョブの設定
Auto-copyジョブを設定するには、既存のCOPY構文にJOB CREATEパラメータを追加します。
COPY lineorder FROM 's3://cm-datalake-20241031/lineorder/'
IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'
IGNOREHEADER 1
DELIMITER '\t'
FORMAT AS CSV
COMPUPDATE off
JOB CREATE job_lineorder AUTO ON;
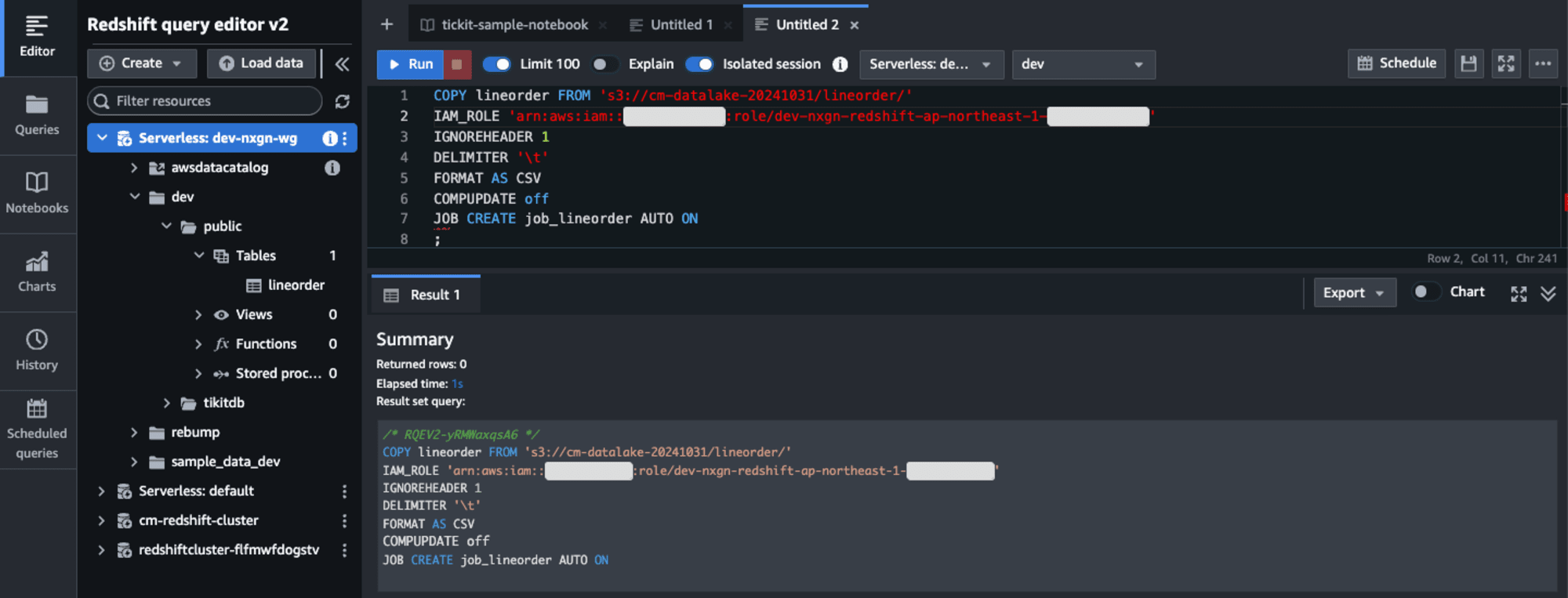
この設定により、指定したS3パスに新しいファイルが追加されると自動的にRedshiftテーブルにロードされます。
Auto-copyジョブを試してみる
では、準備が整いましたので、Auto-copyジョブを試してみます。
最初に、S3バケットにファイルをアップロードします。
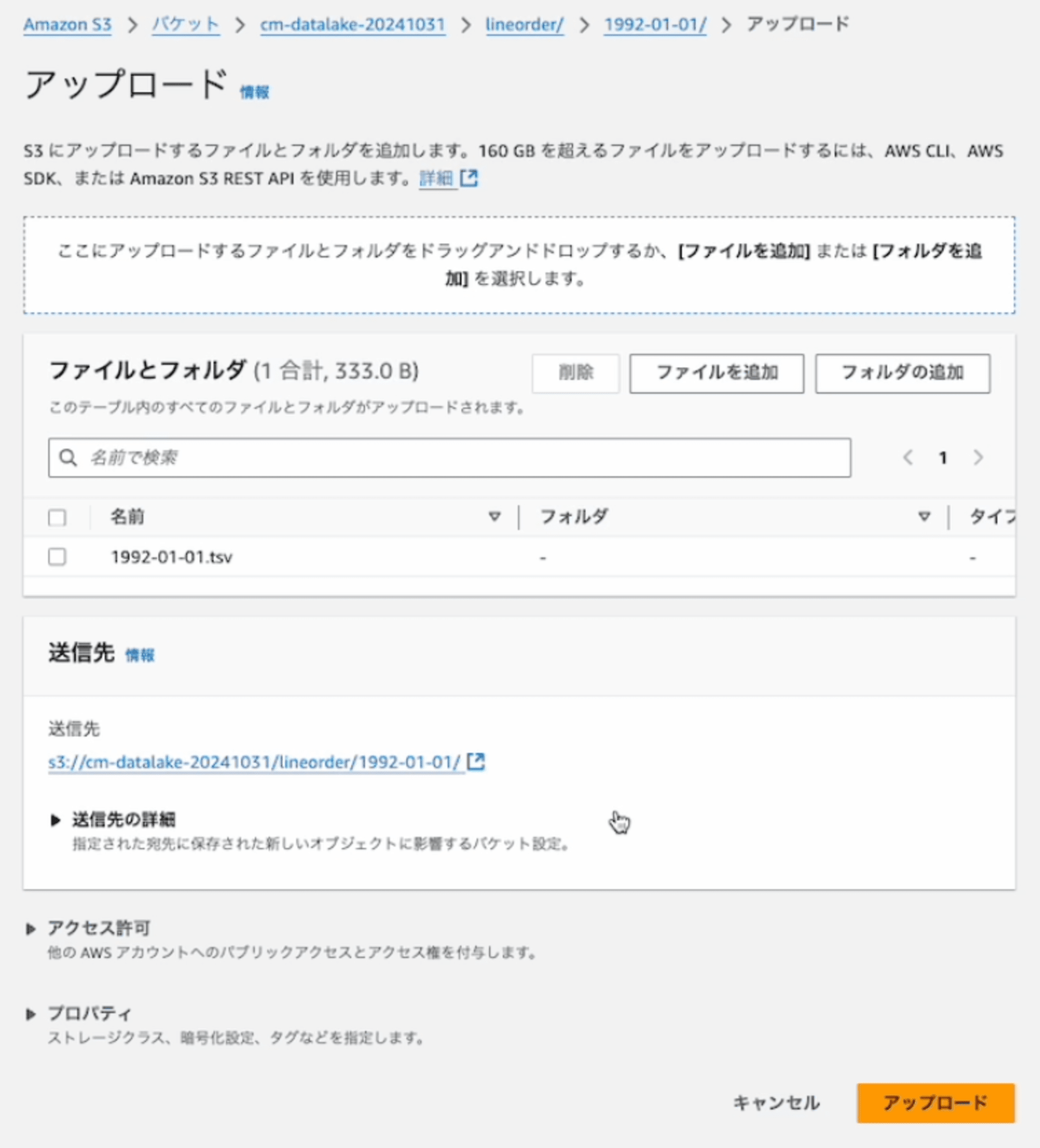
10秒程度で、自動的にファイルの内容が取り込まれました。

3つのファイルをアップロードして、自動的にファイルの内容が取り込まれました。取り込まれる時間は、10秒から60秒程度と差がありましたので、頻繁にファイルを送るとある程度まとめて処理されるのかもしれません。

各ファイルの結果は以下のとおりです。マネジメントコンソールの操作によるものでエンドツーエンドのラウンドトリップを含みます。3つ目のファイルの取込が遅れたことが確認できます。
- ファイル1: 1992-01-01.tsv - 12秒
- 12:50:26に送信済み
- 12:50:38にロード済み
- ファイル2: 1992-01-02.tsv - 16秒
- 12:51:03に送信済み
- 12:51:19にロード済み
- ファイル3: 1992-01-03 - 55秒
- 12:51:31に送信済み
- 12:52:26にロード済み
Auto-copyジョブを手動で実行する
Auto-copyジョブを一時停止したり、手動で実行したりする必要がある場合があります。
COPY JOB RUN job_lineorder;
自動実行を無効にするには、以下のコマンドを実行します。
COPY JOB ALTER job_lineorder
AUTO OFF;
Auto-copyジョブのエラー処理と監視
Auto-copyジョブは、指定されたS3フォルダを継続的に監視し、新しいファイルが作成されるたびに取り込みを実行します。エラーが発生した場合、ジョブはシステムテーブルにログを記録します。以下のシステムテーブルを使用して監視やトラブルシューティングを行うことができます。
- SYS_COPY_JOB:Auto-copyジョブのリスト
- SYS_LOAD_HISTORY:ジョブの集計メトリクス
- STL_LOAD_COMMITS:処理されたファイルの状態と詳細
- STL_LOAD_ERRORS:取り込みに失敗したファイルの詳細
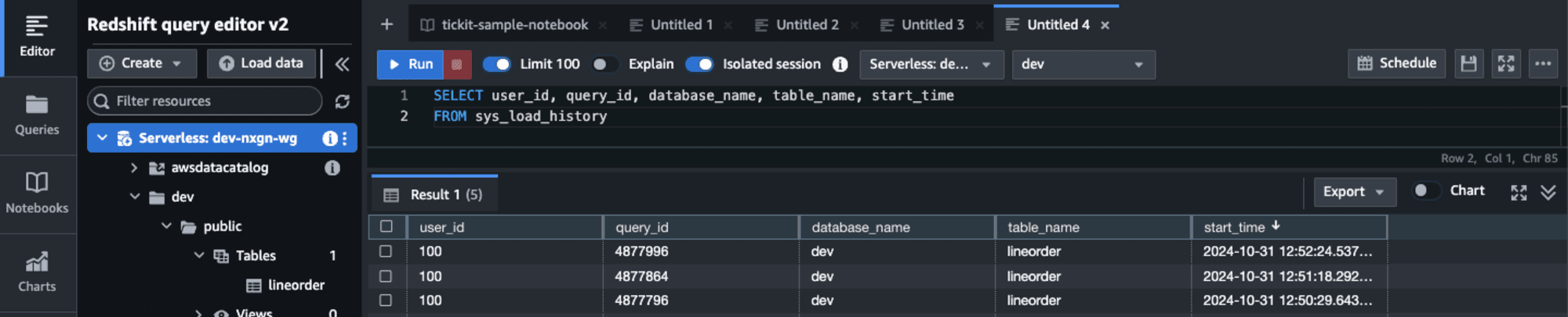
SYS_LOAD_HISTORYビューから取り込まれた状況を確認します。
Auto-copyジョブのベストプラクティス
Auto-copyジョブを効果的に使用するためのベストプラクティスは以下の通りです:
- 各ファイルに一意のファイル名を使用する
- 既存のファイルを更新または上書きしない
- 既に処理されたファイルを再取り込みする場合は、通常のCOPYステートメントを使用する
- ファイル追跡履歴をリセットする場合は、Auto-copyジョブを削除して再作成する
Auto-copyジョブの注意点
Auto-copyジョブを使用する際の主な注意点は以下の通りです。
- S3プレフィックス内の同じ名前のファイルはロードされません。
- 一部の機能はサポートされていません
最後に
Amazon RedshiftのAuto-copy機能によって、AWSのサービス以外からもS3を経由してRedshiftへのデータ取り込みがこれまで以上に簡単になりました。この新機能を活用することで、データパイプラインの構築が簡素化され、最新のデータにアクセスするためのプロセスが効率化されます。Auto-copy機能は、Amazon Redshift ServerlessとAmazon Redshift Provisioned(RA3インスタンス)で利用可能です。










